

kaggle 필사 스터디 3주 차에서는 브라질 보험회사 데이터를 통해 보험을 청구할 확률에 대해 예측하는 코드를 학습했습니다

위와 같은 프로세스로 진행되었습니다
데이터 관찰
기본 정보로 59만개 train 데이터, 89만개 test 데이터가 있다는 점을 알 수 있습니다.
Feature가 정확히 무엇인지 모르고 binary, categorical, interval 혹은 Ordinal feature인지만 구분합니다.
feature -1이면 결측 치/ target은 1: 보험처리를 함, 0: 보험처리를 하지 않음이란 특징을 가지고 있습니다.
Metadata

데이터 관리를 위해 메타데이터용 데이터프레임을 만들었는데 이런 방법은 특정 변수를 선택하거나 시각화, 모델링 할때 유용할 수 있습니다.
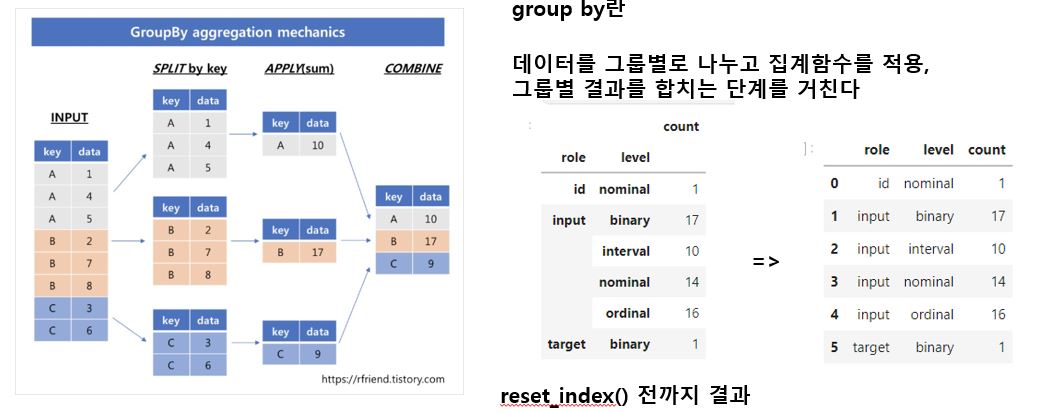
groupby 함수를 공부했습니다.
기술 통계량

캐글 코드에서 describe()함수로 알 수 있는 사실을 배웠습니다.
1. feature의 결측치 존재 유무
2 .min, max 값으로 스케일링의 필요성
3. max 값으로 변수의 값이 비율인지 확인 (예: cs_calc_00 feature들은 최대가 0.9이다)
불균형 클래스 핸들링

위에서 불균형 클래스가 존재함을 발견하고 해결하고자 했습니다. 해당 데이터는 1이 압도적으로 많은 상황으로 오버샘플링과 언더샘플링 방식 중 언더샘플링 방식을 이용했습니다.
캐글 코드는 undersampling rate를 계산 -> shuffle 적용 -> 추출한 인덱스와 기존 target 1인 인덱스 합치기 -> 해당 인덱스 버린 데이터프레임 저장 과정을 거쳤습니다.

sklearn shuffle를 이용하면 일정한 방식으로 배열이나 행렬을 섞을 수 있습니다.
random_state = 셔플링을 위한 난수 설정, 반복 시 같은 결과를 얻고 싶다면 난수 설정
n_samples = 생성할 샘플의 길이, 설정 안 하면 원래 배열의 첫 번째 차원으로 설정
Data quality 확인

sklearn의 simpleinputer함수를 이용해 결측 치 확인 및 대체를 했습니다. 이 코드는 평균값으로 대체합니다.
데이터 시각화

Seaborn은 Matplotlib을 기반으로 한 시각화 패키지입니다.


그래프를 그리는 2가지 함수의 파라미터를 알아보았습니다.

상관관계도 알아보았습니다. color 팔레트에 여러 종류가 있는데 만약 발산하는 팔레트면 diverging_palette 라고 합니다.
heatmap()의 파라미터
데이터프레임, 색깔, vmax=최댓값, center = 중앙값, linewidths = 셀 사이마다 선, annot = 각 셀 마다 값 표시 여부 이때 fmt 지정 필요, fmt = 데이터 형태, cbar = colorbar의 유무
Feature engineering

더미변수에 대해 알아보았습니다. 머신러닝에서 모든 변수를 수치화 할 필요가 있습니다. 하지만 요일을 단순히 수치형 변수로 바꾸면 1+2= 3 등 관계성이 생겨서 더미변수를 사용하는데 캐글 필사에선 get_dummies함수를 썼습니다.


Feature selection

다음은 feature를 선택하는 단계입니다.

낮은 분산을 가진 feature를 제거해주는 함수입니다. 하지만 낮은 분산이 꼭 상관관계가 없는 것은 아니기때문에 신중하게 사용할 필요가 있다고 합니다.

트리 기반 모델에서 내장된 함수인데 배열 형태로 feature 중요도를 반환합니다.

중요도가 임계치 이상인 feature를 모두 선택하는 함수입니다.
Feature scaling

해당 캐글코드에서 StandardScaler()를 사용했고 평균을 0, 표준편차 1로 데이터 범위를 조정했습니다.
'3-1기 스터디 > 캐글 필사' 카테고리의 다른 글
| [6주차] Zillow House Value Prediction (0) | 2021.11.29 |
|---|---|
| [5주차] Dynamics of New York city - Animation (0) | 2021.11.17 |
| [4주차] Costa Rican Household Poverty Level Prediction (0) | 2021.11.14 |
| [2주차] 타이타닉 데이터 분석 : 생존율 예측하기 (0) | 2021.10.17 |
| [1주차] 캐글 시스템의 이해 (2) | 2021.10.09 |




댓글