

kaggle 필사 스터디 2주 차에서는 타이타닉 데이터를 분석하여 생존율을 예측하는 코드를 공부했습니다.
위는 저희가 사용한 타이타닉 데이터이며, 아래는 필사한 코드 중 일부로 학습 모델에 정돈된 데이터를 넣어 예측율을 구하는 과정입니다.
이번 타이타닉 생존율 예측하기 데이터 분석은 아래와 같은 전체적인 프로세스를 갖고 있었습니다.
먼저 데이터셋을 확인(어떤 feature들을 갖고 있는지 또는 null data 존재 유무등을 파악)하고, 탐색적 데이터 분석, exploratory data analysis를 통해 데이터를 탐색했습니다.
그다음 모델에 넣을 데이터를 모델의 성능 향상을 위해 engineering하여 sickit learn을 이용해 학습 모델을 만들고, 모델을 학습시킨 후, 예측 성능이 원하는 수준인지 평가하는 과정을 차례로 거쳤습니다.
필사를 진행하면서 새롭게 배웠던 점이나 헷갈렸던 개념들을 다시 한번 정리해보았습니다.
EDA
먼저 탐색적 데이터 분석(EDA), 데이터 분석 기법입니다.
이 데이터 분석 방법은 원래, 원 상태의 데이터를 통해 유연하게 데이터를 탐색하는 방법으로 데이터에 대한 탐색과 이해를 기본으로 합니다.
수집된 데이터를 시각화하여 탐색하여 어떠한 패턴이 보이는지를 확인하고, 여기서 인사이트 얻어 분석을 진행하는 방식입니다.
이번 titanic 데이터 분석에서도 이와 같이 각 feature 들을 개별적으로 분석하고, feature 들 간의 상관관계 확인, 그리고 여러 시각화 툴을 사용하는 등 탐색적 데이터 분석 방법을 통해 insight를 얻었습니다.
Skewness
다음으로, Skewness입니다.
비대칭도를 뜻하며 데이터 분포가 정규 분포가 아니라 한쪽으로 치우친 상태를 말합니다.
이렇게 편향된 데이터를 그대로 학습 모델에 넣을 경우 꼬리 부분이 다른 부분에 비해 상대적으로 모델에 영향을 미치지 못한 채로 학습되기 때문에 데이터를 변환해주어야 좋습니다.
왼쪽은 변환을 거치지 않은(skewed) 타이타닉의 fare feature 데이터의 그래프이고 이고, 오른쪽은 변환을 거친 후를 나타내는 그래프입니다.
이처럼 왼쪽으로 치우진 것을 positive/left skewness 하며 반대로 오른쪽은 negative/right skewness 합니다.
이렇게 치우진 데이터는 변환을 해주어야 하는데 여러가지 방법 중 titanic data는 log를 씌워 변환했습니다.
Null data 처리
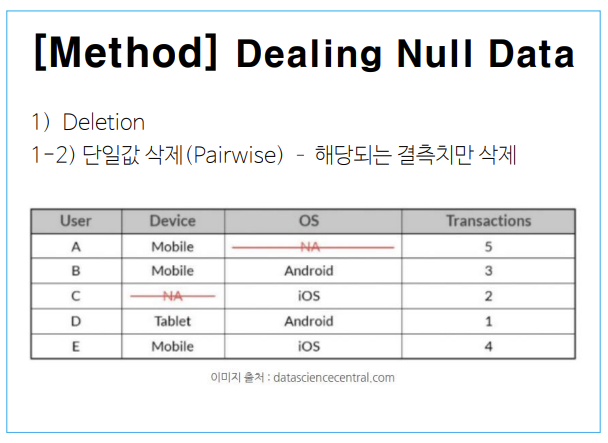


결측치 처리 방법입니다.
예측 모델을 만들고 있기 때문에 결측치를 어떻게 처리하냐에 따라 모델의 성능이 좌우됩니다. 즉, 결측치를 잘못 처리하고 진행한다면 결과에 악영향을 끼치지 때문에 결측치 처리는 데이터 분석에서 중요한 분야라고 할 수 있습니다.
이런 null data를 처리하는데는 크게 두가지 방법이 있고 또 세부적으로 두 가지로 나누어집니다.
1. deletion(제거) 방법
1-1) 결측치가 존재하는 전체 행을 모두 삭제하는 방법
1-2) 해당 결측치만 삭제하는 단일값 삭제 방법
2. imputation(보간) 방법
2-1) 평균값으로 채우는 방법
2-2) 예측하여 값을 채워 넣는 predictive 방법(회귀 분석, svm, 머신러닝 알고리즘 등 다양)
이번 titanic의 age faeature의 경우에는 imputation의 평균값을 채워 넣는 방법을 사용해 평균 나이로 null data를 채워주었습니다.
Pearson Correlation

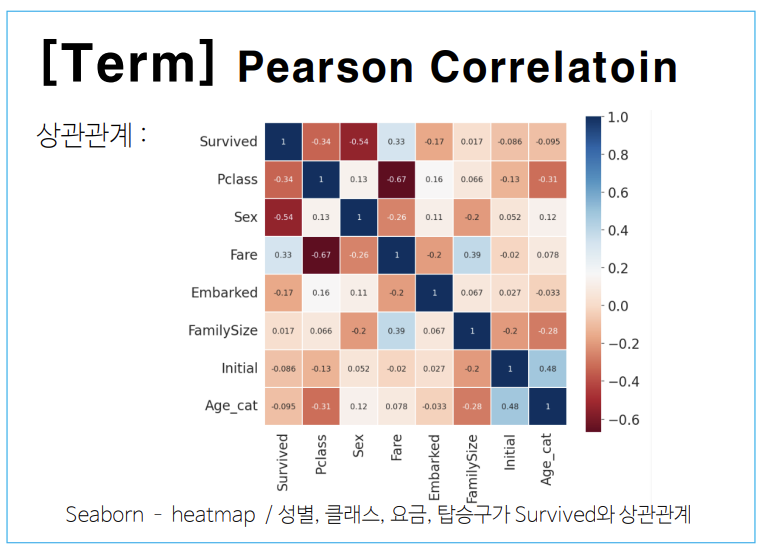
상관관계로 두 변수가 어떤 선형 관계를 갖고 있는지를 나타내는 값입니다.
서로 같이 변하는 정도와 서로 각기 변하는 정도를 통해 이 값을 계산할 수 있습니다.
-1에 가까울수록 음의 상관관계, 1에 가까울수록 양의 상관관계, 0은 상관관계가 없음을 의미합니다.
titanic 데이터도 feature 상관관계를 heatmap 그래프(오른쪽)로 시각화하였고, 이를 통해 성별(Sex), 클래스(Pclass), 요금(Fare), 탑승구(Embarked)가 생존(Survived)과 상관관계가 있음을 알 수 있습니다.
one-hot encoding


one-hot encoding은 문자형 데이터와 같이 사람은 알아보기 쉬운 데이터이나 컴퓨터는 바로 인식하기 어려운 데이터들을 숫자 값으로 변환하는 것을 말합니다.
우리가 표현하고 싶은 데이터는 1로 나머지는 0으로 표시합니다.
이 방식은 표현하고 싶은 데이터가 증가할수록 필요한 저장공간 또한 증가한다는 단점이 있습니다.
titanic 데이터에서 initial과 embarked feature를 one-hot encoding을 통해 다음과 같이 변환시켜 주었습니다.
scikit-learn library/Randomforest 알고리즘
사이킷런 라이브러리로 이번 타이타닉 모델을 빌드할 때 쓴 라이브러리입니다.
파이썬 대표 오픈소스 머신러닝 라이브러리로 많이 쓰이고 있는 유명한 라이브러리이기도 합니다.
사이킷런은여러 머신러닝 알고리즘을 지원하고 있어 크게 classification, regression, clustering 등으로 나눌 수 있습니다.
titanic과 같은 생존을 나타내는 1, 0을 이루어져 있는 binary classification 문제이기 때문에 사이킷런의 Randomforest알고리즘을 이용했습니다.
이 Randomforest 알고리즘을 알기 위해서는 먼저 결정 트리 개념을 알아야 합니다.
결정 트리는 분류 규칙을 통해 데이터를 분류하는 지도 학습 모델 중 하나로 위 그림은 결정 트리를 도식화해 놓은 것입니다.
보시는 것처럼 특정 기준에 따라 데이터를 구분하고 있습니다.
이러한 결정 트리들이 모여 Randomforest를 구성하게 됩니다.
EX)
feature가 30개라면, 랜덤으로 5개의 feature만 선택하여 결정 트리를 만듭니다.
이렇게 랜덤한 feature를 뽑아 결정 트리를 만드는 과정을 반복하게 되면 결정 트리에서 가장 많이 나온 결과값이 최종 예측 결과가 되는 것입니다.
위 그림처럼 여러 개의 결정 트리를 만들고 이를 결과들을 통합, ensamble(앙상블)하여 최종 결과를 도출해 냅니다.
"어떠한 문제를 해결할 때, 한 명의 똑똑한 사람보다 100명의 평범한 사람들이 머리를 맞대면 더 잘 풀 수 있는 원리"
이후 함께 캐글 필사를 진행하면서 느꼈던 점이나 어려웠던 점, 궁금한 점들을 서로 자유롭게 나누며 2주차 스터디를 마무리하였습니다! 😎
'3-1기 스터디 > 캐글 필사' 카테고리의 다른 글
| [6주차] Zillow House Value Prediction (0) | 2021.11.29 |
|---|---|
| [5주차] Dynamics of New York city - Animation (0) | 2021.11.17 |
| [4주차] Costa Rican Household Poverty Level Prediction (0) | 2021.11.14 |
| [3주차] 자동차 보험회사 데이터분석 (0) | 2021.11.07 |
| [1주차] 캐글 시스템의 이해 (2) | 2021.10.09 |




댓글