
1. 키 종류에 대해 설명해주세요
- 슈퍼키(Super Key) : 유일성을 만족하는 키
- 복합키(Composite Key) : 2개 이상의 속성(attribute)를 사용한 키
- 후보키(Cnadidate Key) : 유일성과 최소성을 만족하는 키. 기본키가 될 수 있는 후보이기 때문에 후보키라고 불린다.
- 기본키(Primary key) : 후보키에서 선택된 키. NULL 값이 들어갈 수 없으며, 기본키로 선택된 속성은 동일한 값이 들어갈 수 없다.
- 대체키(Surrogate key) : 후보키 중에서 기본키로 선택되지 않은 키
- 외래키(Foreign Key) : 어떤 테이블(Relation)간의 기본키를 참조하는 속성이다. 테이블들 간의 관계를 나타내기 위해서 사용된다.
2. 인덱스란 무엇이고, 어떻게 동작 하나요?
인덱스는 데이터베이스에서 조회 및 검색을 더 빠르게 할 수 있는 방법/기술, 혹은 이에 쓰이는 자료구조 자체를 의미합니다.
- select 문을 사용하여 원하는 조건의 데이터를 검색할 때, 저장된 데이터의 양이 엄청나게 많다면 검색을 위한 순회에 많은 자원과 시간이 소모됩니다. 이럴 때 인덱스를 사용합니다.
동작
- Index Table에서 where 에 포함된 값을 검색
- 해당 값의 table_id PK를 획득
- 가져온 table_id PK값으로 원본 테이블에서 값을 조회
DBMS는 인덱스를 다양한 알고리즘으로 관리를 하고 있는데 일반적으로 사용되는 알고리즘은 B+Tree 알고리즘이다.

3. Table Full Scan과 Index Range Scan 을 설명해주세요.
Table Full Scan
- 테이블에 속한 블록 전체를 읽어서 사용자가 원하는 데이터를 찾음
- 시퀀셜 액세스 + Multi Block I/O
- Table Full Scan는 피해야한다는 인식이 많지만, 오히려 인덱스를 사용하는 것이 성능을 떨어뜨리는 경우가 더 많다.
- 캐시에서 못 찾으면 한 번의 I/O Call 로 인접한 수십-수백개의 블록을 한꺼번에 불러오는 것이 좋다.
Index Range Scan
- 인덱서 선두 컬럼이 가공되지 않은 상태로 조건절에 있어야 Index Range Scan이 가능
- 인덱스에서 일정량을 스캔하면서 얻은 ROWID로 테이블 레코드를 찾는다.
- 소량의 데이터를 찾을 때 테이블 전체를 스캔하는 것은 비효율적이므로, 큰 테이블에서 소량의 데이터를 찾을 대는 반드시 인덱스를 사용해야 한다.
- 인덱스는 큰 테이블에서 아주 적은 일부의 데이터를 빨리 찾기 위한 도구일 뿐, 읽을 데이터가 일정 수량을 넘으면 인덱스보다는 Table Full Scan을 사용하는것이 유리하다.
4. JOIN에 대해 설명해 주세요.
조인이란, 한 데이터베이스 내의 여러 테이블의 레코드를 조합하여 하나의 열로 표현한 것입니다. 따라서 조인은 테이블로서 저장되거나, 그 자체로 이용할 수 있는 결과 셋을 만들어냅니다.
조인의 종류
- 내부 조인 (INNER JOIN)
- 여러 애플리케이션에서 사용되는 가장 흔한 결합 방식이며, 기본 조인 형식으로 간주된다.
- 조인 구문에 기반한 2개의 테이블(A, B)의 컬럼 값을 결합하믕로써 새로운 결과 테이블을 생성한다.
- 외부 조인 (OUTER JOIN)
- 조인 대상 테이블에서 특정 테이블의 데이터가 모두 필요한 상황에서 외부 조인을 활용하여 효과적으로 결과 집합을 생성할 수 있다.
- LEFT OUTER JOIN : 우측 테이블에 조인할 컬럼의 값이 없는 경우 사용한다. 즉, 좌측 테이블의 모든 데이터를 포함하는 결과 집합을 생성한다.
- RIGHT OUTER JOIN : 동일
- FULL OUTER JOIN : 양쪽 테이블 모두 OUTER JOIN이 필요할 때 사용한다.
- 셀프 조인 (SELF JOIN) : 한 테이블에서 자기 자신에 조인을 시키는 것이다.
5. 파티셔닝에 대해 설명해주세요.
파티셔닝(Partitioning)은 큰 table이나 index를 관리하기 쉬운 partition이라는 작은 단위로 물리적으로 분할하는 것을 의미합니다.
파티셔닝 기법을 통해 소프트웨어적으로 데이터베이스를 분산 처리하여 성능이 저하되는 것을 방지하고 관리를 보다 수월하게 할 수 있습니다.
파티셔닝의 장점
- 관리적 측면 : partition 단위 백업, 추가, 삭제, 변경
- 전체 데이터를 손실할 가능성이 줄어들어 데이터 가용성이 향상된다.
- partition 별로 백업 및 복구가 가능하다.
- partition 단위로 I/O 분산이 가능하여 UPDATE 성능을 향상시킨다.
- 성능적 측면 : partition 단위 조회 및 DML 수행
- 데이터 전체 검색 시 필요한 부분만 탐색해 성능이 증가한다.
- 즉, Full Scan에서 데이터 Access의 범위를 줄여 성능 향상을 가져온다.
- 필요한 데이터만 빠르게 조회할 수 있기 때문에 쿼리 자체가 가볍다.
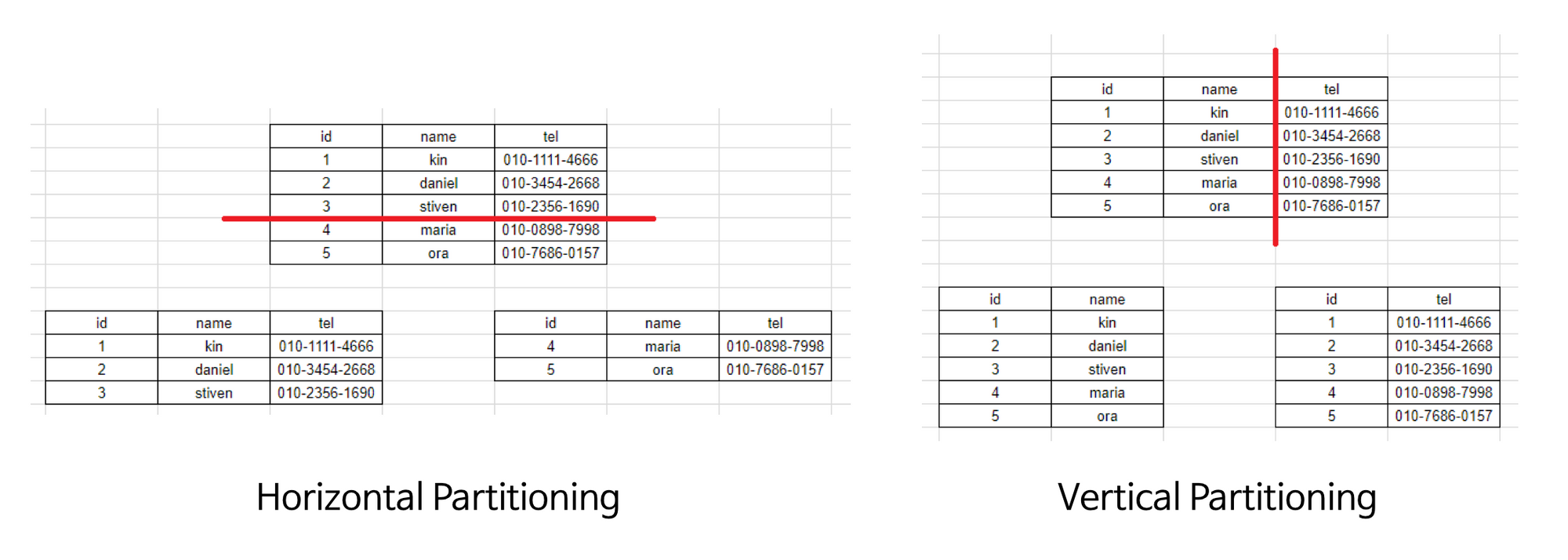
파티셔닝의 종류
- 수평 (horizontal) 파티셔닝
- 샤딩(Sharding)과 동일
- 수직 (vertical) 파티셔닝
6. ORM이란 무엇인가요?
ORM이란 Object-Relational Mapping (객체-관계 매핑) 의 약자로, 객체와 관계형 데이터베이스의 데이터를 자동으로 매핑(연결)해주는 것을 말합니다.
영속성(Persistence)
- 데이터를 생성한 프로그램의 실행이 종료되더라도 사라지지 않는 데이터의 특성
- 영속성을 갖지 않는 데이터는 단지 메모리에서만 존재하기 때문에 프로그램을 종료하면 모두 잃어버리게 된다. 때문에 파일 시스템, 관계형 데이터베이스 혹은 객체 데이터베이스 등을 활용하여 데이터를 영구하게 저장하여 영속성을 부여한다.

ORM의 장점
- 객체 지향적인 코드로 인해 더 직관적이고 비즈니스 로직에 더 집중할 수 있게 도와준다.
- 선언문, 할당, 종료 같은 부수적인 코드가 없거나 급격히 줄어든다.
- 각종 객체에 대한 별도로 작성하기 때문에 코드의 가독성을 올려준다.
- SQL의 절차적이고 순차적인 접근이 아닌 객체 지향적인 접근으로 인해 생산성이 증가한다.
- 재사용 및 유지보수의 편리성이 증가한다.
- ORM은 독립적으로 작성되어 있고, 해당 객체들을 재활용 할 수 있다.
- 때문에 모델에서 가공된 데이터를 컨트롤러에 의해 뷰와 합쳐지는 형태로 디자인 패턴을 견고하게 다지는데 유리하다.
- 매핑정보가 명확하여, ERD를 보는 것에 대한 의존도를 낮출 수 있다.
- DBMS에 대한 종속성이 줄어든다.
- 대부분 ORM 솔루션은 DB에 종속적이지 않다. 즉, 구현 방법 뿐만 아니라 많은 솔루션에서 자료형 타입까지 유효하다.
- 프로그래머는 Object에 집중함으로 극단적으로 DBMS를 교체하는 거대한 작업에도 비교적 적은 리스크와 시간이 소요된다.
- 또한 자바에서 가공할 경우 equals, hashCode의 오버라이드 같은 자바의 기능을 이용할 수 있고, 간결하고 빠른 가공이 가능하다.
단점
- 완벽한 ORM으로만 서비스를 구현하기가 어렵다.
- 프로젝트의 복잡성이 커질 경우 난이도 또한 올라갈 수 있다.
- 잘못 구현된 경우에 속도 저하 및 심각할 경우 일관성이 무너지는 문제점이 생길 수 있다.
- 일부 자주 사용되는 대형 쿼리는 속도를 위해 SP를 쓰는 등 별도의 튜닝이 필요한 경우가 있다.
- DBMS의 고유 기능을 이용하기 어렵다.
- 프로시저가 많은 시스템에선 ORM의 객체 지향적인 장점을 활용하기 어렵다.
7. 트랜젝션에 대해 설명해 주세요.
- 트랜잭션(Transaction)이란, 데이터베이스의 상태를 변환시키는 논리적인 작업 단위를 구성하는 연산들의 집합입니다.
- 하나의 트랜잭션은 Commit 되거나 Rollback 된다.
- Commit : 한개의 논리적 단위에 대한 작업이 성공적으로 끝나 데이터베이스가 다시 일관된 상태에 있을 때, 이 트랜잭션이 행한 갱신 연산이 완료된 것을 트랜잭션 관리자에게 알려주는 연산이다.
- Rollback : 하나의 트랜잭션 처리가 비정상적으로 종료되어 데이터베이스의 일관성을 깨뜨렸을 때, 이 트랜잭션의 일부가 정상적으로 처리되었더라도 트랜잭션의 원자성을 구현하기 위해 이 트랜잭션이 행한 모든 연산을 취소(Undo)하는 연산이다.
- 하나의 트랜잭션은 Commit 되거나 Rollback 된다.

- 트랜잭션의 성질
- 원자성(Atomicity) : 트랜잭션의 모든 연산들은 정상적으로 수행 완료되거나 아니면 전혀 어떠한 연산도 수행되지 않은 상태를 보장해야 한다.
- 일관성 (Consistency) : 트랜잭션 완료 후에도 데이터베이스가 일관된 상태로 유지되어야 한다.
- 독립성 (Isolation) : 하나의 트랜잭션이 실행하는 도중에 변경한 데이터는 이 트랜잭션이 완료될 때까지 다른 트랜잭션이 참조하지 못한다.
- 지속성 (Durability) : 성공적으로 수행된 트랜잭션은 영원히 반영되어야 한다.
8. 정규화의 종류에 대해 말해주세요.
관계형 데이터베이스에서 데이터 중복을 최소화하고 데이터를 구조화하는 것을 정규화라고 한다. 정규화 과정으로는 대표적으로 제 1정규형, 제 2정규형, 제 3정규형이 있다.
- 제 1 정규형 : 테이블의 한 셀이 복합적인 값을 가지지 않는 상태를 제 1 정규형이라고 한다. 여기서 셀은 하나의 튜플이 가지는 속성값을 말하며, 복합적인 값은 배열 값을 의미한다.
- 제 2 정규형 : 테이블에서 부분함수 종속이 없는 상태를 제 2정규형이라고 한다. 기본키가 하나뿐인 테이블은 자동적으로 제 2 정규형을 만족하게 된다.
- 제 3 정규형 : 제 2 정규형에서 추이함수 종속을 제거한 상태를 제 3 정규형이라고 한다. 추이함수 종속이란 기본키 이외의 속성과 다른 속성간 함수 종속이 존재하는 것을 말한다.
9. 정규화의 목적은 무엇인가요?
- 데이터베이스 변경 시 이상 현상 (Anomaly) 제거하여 각종 이상 현상들이 발생하는 문제점을 해결하기 위해 사용.
- 데이터베이스 구조 확장 시 재 디자인 최소화. 정규화 된 데이터베이스 구조에서는 새로운 데이터 형의 추가로 인한 확장 시, 그 구조를 변경하지 않아도 되거나 일부만 변경해도 된다.
- 사용자에게 데이터 모델을 더욱 의미있게 제공하기 위해 한다. 정규화된 테이블들과 정규화된 테이블들간의 관계들은 현실 세게에서의 개념들과 그들간의 관계들을 반영한다.
'3-2기 스터디 > 기술 면접 대비' 카테고리의 다른 글
| [기술 면접 대비] 5주차- 운영체제 (0) | 2022.05.10 |
|---|---|
| [기술 면접 대비] 3주차- 네트워크 (0) | 2022.04.17 |
| [기술 면접 대비] 2주차 - 알고리즘 (0) | 2022.04.10 |
| [기술 면접 대비] 1주차-개발 상식 (0) | 2022.04.06 |




댓글