
CS 스터디 2주차
1. quick sort가 일어나는 과정과 시간복잡도(최선/최악)를 설명하세요
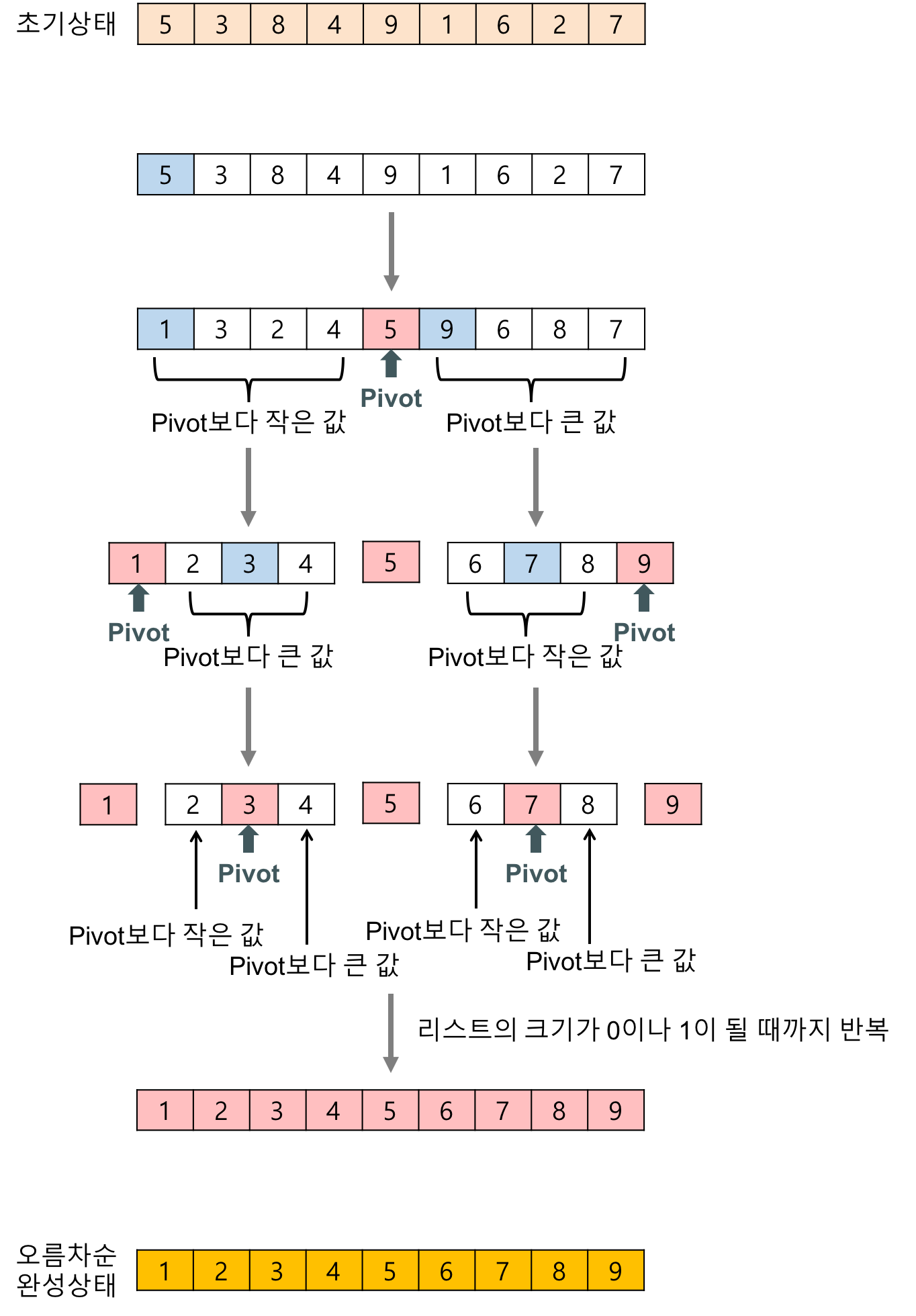
- 퀵정렬 : 분할 정복 알고리즘의 하나로, 리스트를 비균등하게 분할한다.
- 리스트 안의 한 요소를 선택하여 피벗(pivot)이라 한다.
- 피벗을 기준으로 피벗보다 작은 요소들은 모두 피벗의 왼쪽으로 옮겨지고, 피벗보다 큰 요소들은 모두 피벗의 오른쪽으로 옮겨진다.
- 피벗을 제외한 왼쪽 리스트와 오른쪽 리스트를 다시 정렬한다. 분할된 부분 리스트에 대하여 순환 호출을 이용하여 정렬을 반복한다.
- 부분 리스트들이 더 이상 분할이 불가능할 때까지 반복한다.과정
- 최선의 경우 T(n) = O(nlog2n)
- 최악의 경우 T(n) = O(n^2)
- 평균 T(n) = O(n^2)
(출처 https://gmlwjd9405.github.io/2018/05/10/algorithm-quick-sort.html)
2. Heap sort가 일어나는 과정과 시간복잡도를 설명해주세요
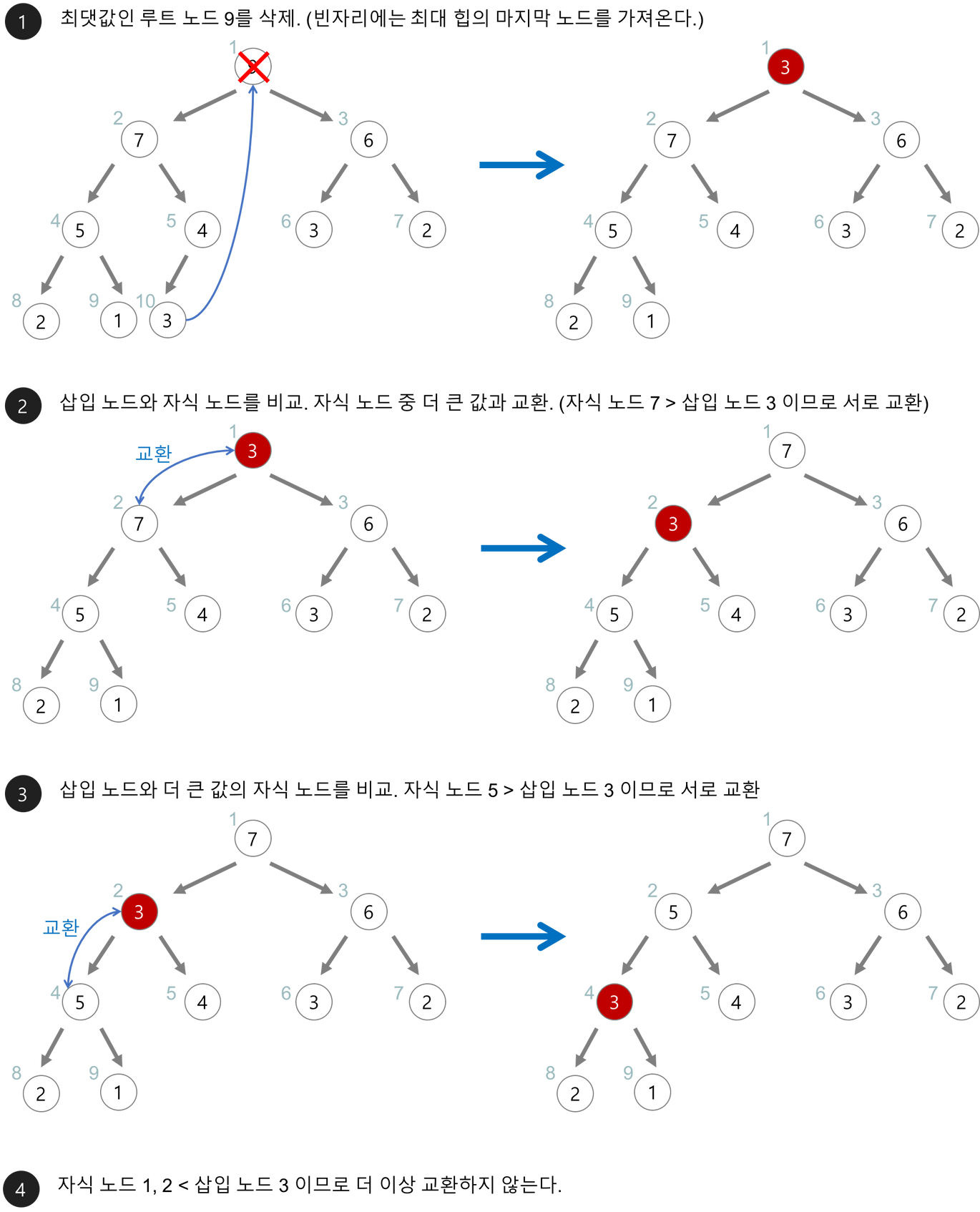
- 힙정렬 : 최대 힙 트리나 최소 힙 트리를 구성해 정렬하는 방법
- 내림차순 정렬을 위해서는 최대 힙을 구성하고, 오름차순 정렬을 위해서는 최소힙을 구성한다.
- 과정
- 정렬해야 할 n개의 요소들로 최대 힙(완전 이진 트리 형태)을 만든다.
- 그 다음으로 한번에 하나씩 요소를 힙에서 꺼내서 배열의 뒤부터 저장한다.
- 삭제되는 요소들은 값이 감소되는 순서로 정렬된다.
최대힙의 삽입

최대 힙의 삭제
힙 정렬의 시간 복잡도
- 힙 트리 전체의 높이가 log2n 이므로 하나의 요소를 힙에 삽입하거나 삭제할 때 힙을 재정비하는 시간이 그만큼 소요된다.
- T(n) = O(nlog2n)
(출처 : https://gmlwjd9405.github.io/2018/05/10/algorithm-heap-sort.html)
3. 해시테이블과 이진 검색트리를 비교하고 장단점을 이야기해주세요

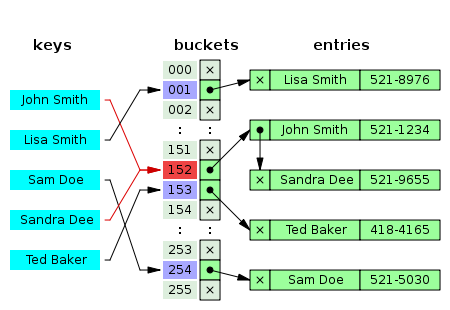
- 해시테이블은 효율적인 탐색을 위한 자료구조로, key값을 value에 1:1로 연관지어 저장한다. 해싱은 임의의 길이의 값을 해쉬 함수를 통해 고정된 크기의 값으로 변환하는 작업을 말하는데, 키 값을 해시 코드로 변환 후 해당 해시 코드로 배열의 인덱스를 참조하여 값을 찾는다.
- HashTable을 사용하면 적은 리소스로 많은 데이터를 효율적으로 관리할 수 있고, 배열의 인덱스를 사용하기 때문에 빠른 검색, 삽입, 삭제가 가능하다. 또 Key와 Hash에 연관성이 없어 보안적으로 유리하며, 중복 제거에 유용하다.
- 단점은 충돌 발생 가능성이 있고, 공간 복잡도가 증가하며 해시 함수에 의존해야한다는 단점이 있다.
- 이진탐색트리는 이진 탐색과 연결 리스트를 결합한 자료구조이다. 이진 탐색의 효율적인 탐색 능력을 유지하면서, 빈번한 자료 입력과 삭제가 가능하다.
4. stack과 queue의 차이점은 무엇인가요?
- Stack은 먼저 넣는 자료가 마지막으로 나오게 되는 First-In-Last-Out 구조이고, Queue는 먼저 넣는 자료가 가장 먼저 나오는 First-In-First-Out 구조이다.
- Stack은 Array로 구현하면 삭제할 필요 없이 index를 줄이고 초기화만 하면 되므로, Array로 구현하는 것이 좋고, Queue는 삽입과 삭제가 용이한 LinkedList로 구현하는 것이 좋다.
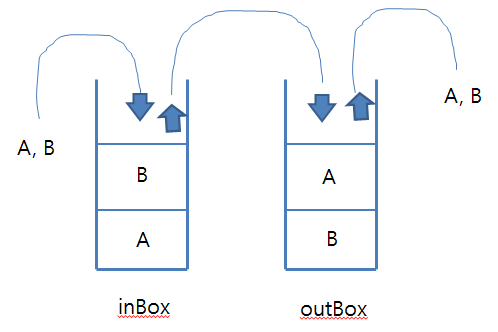
5. 두개의 stack을 이용해 queue를 구현하려면 어떤 식으로 해야 할까요?
public class Queue {
private Stack inBox = new Stack();
private Stack outBox = new Stack();
public void enQueue(Object item) {
inBox.add(item);
}
public Object deQueue() {
if (outBox.isEmpty()) {
while(!inBox.isEmpty()) {
outBox.push(inBox.pop());
}
}
return outBox.pop();
}
public static void main(String[] args) {
Queue queue = new Queue();
queue.enQueue("A");
queue.enQueue("B");
queue.enQueue("C");
System.out.println(queue.deQueue());
System.out.println(queue.deQueue());
System.out.println(queue.deQueue());
}
}
- inBox에 있는 데이터를 push 하고, 다시 pop 하여 outBox에 push 한다. 그 후 다시 outBox에 있는 데이터를 pop 한다.
- 즉, 역순으로 들어가게했다가 다시 그대로 pop 한다.
6. Array와 LinkedList의 차이가 무엇인가요?
- 공간적 제약
- ArrayList는 배열이므로 길이가 고정되어 있습니다. 따라서 배열에 새로운 요소를 추가하려고 할 때, 배열의 용량이 이미 가득 차 있다면 새로운 배열을 생성해주어야 한다. 또 메모리에 여유공간이 없는 경우 에러가 발생할 수도 있다.
- LinkedList : 한 개의 Node는 다른 Node에 대한 참조만 가지고 있다. 따라서 공간적 제약을 ArrayList에 비해 받지 않는다.
- 새로운 요소 추가
- ArrayList : 여유공간이 있는 경우 O(1), 여유 공간이 없는 경우 O(n)
- LinkedList : 새로운 요소를 추가할 때 항상 O(1)
- 임의 접근과 순차 접근
- ArrayList : 임의접근이 가능하므로 O(1)
- LinkedList : 순차접근만 가능하므로 O(n)
- 중간에 새로운 요소 삽입
- ArrayList : 해당 요소 뒤의 요소들도 전부 옮겨야 한다.
- LinkedList : 앞 뒤 요소의 값만 바꾸면 된다.
- 중간에 요소 삭제
- ArrayList : 뒤의 요소들을 전부 앞으로 이동
- LinkedList : 앞 뒤 요소의 값만 바꾼다.
7. DFS와 BFS의 차이를 말해주세요
- DFS는 깊이 우선 탐색 (Depth-First Search)로, 루트 노드에서 시작해서 다음 분기(branch)로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방법이다.
- 모든 노드를 방문하고자 하는 경우 이 방법을 선택한다.
- BFS는 너비 우선 탐색 (Breadth-First Search)으로, 루트 노드에서 시작해서 인접한 노드를 먼저 탐색하는 방법이다.
- 두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때 이 방법을 선택한다.
- ex ) 지구상에 존재하는 모든 친구 관계를 그래프로 표현한 후 Ash와 Vanessa 사이에 존재하는 경로를 찾는 경우.
8. 그래프를 인접리스트/인접 행렬 구현 시 차이점은?
- 인접 리스트(adjacency List) : 모든 정점을 인접 리스트에 저장한다. 즉, 각각의 정점에 인접한 정점들을 리스트로 표시한다. 정점의 번호만 알면 이 번호를 배열의 인덱스로하여 각 정점의 리스트에 쉽게 접근할 수 있다.
- 그래프 내에 적은 숫자의 간선만을 가지는 희소 그래프(Sparse Graph)의 경우 사용.
- 어떤 노드에 인접한 노드들을 쉽게 찾을 수 있고, 그래프에 존재하는 모든 간선의 수는 O(N+E) 안에 알 수 있다.
- 간선의 존재 여부와 정점의 차수를 알기 위해서 정점의 차수만큼의 시간이 필요하다.
- 인접 행렬 (Adjacency Matrix) : N*N Boolean Matrix로, matrix[i][j]가 true라면 i→j 로서의 간선이 있다는 뜻이다.
- 정점(노드)의 개수가 n인 그래프를 인접 행렬로 표현.
- 그래프에 간선이 많이 존재하는 밀집 그래프(Dense Graph)의 경우 사용.
- 두 정점을 연결하는 간선의 존재 여부 (M[i][j])를 O(1) 안에 즉시 알 수 있고, 정점의 차수는 O(N) 안에 알 수 있다.
- 어떤 노드에 인접한 노드들을 찾기 위해서는 모든 노드를 전부 순회해야 한며, 그래프에 존재하는 모든 간선의 수는 O(N^2)만에 알 수 있다. 즉, 인접 행렬 전체를 조사해야 한다.
9. 해시 테이블에서 해시 충돌을 피하기 위한 방법에 대해 설명해주세요.
- Separating Chaining
- JDK 내부에서 사용하는 충돌 처리 방식
- LinkedList 사용 시 충돌이 발생하면 충돌 발생한 인덱스가 가리키고 있는 LinkeList에 노드 추가하여 Value 삽입
- Key에 대한 Value 탐색 시에는 인덱스가 가리키고 있는 LinkedList를 선형 검색하여 Value 반환 (삭제도 같음)
- Open addressing
- 추가 메모리 공간을 사용하지 않고, HashTable 배열의 빈 공간을 사용
- Linear Probing, Quadratic Probing, Double Hashing 등의 방법
- Resizing
- 저장 공간이 일정 수준 채워지면 Separating Chaining의 경우 성능 향상을 위해, Open addressing의 경우 배열 크기 확장을 위해 Resizing.
10.벨만포드 알고리즘과 다익스트라 알고리즘의 차이점을 이야기해주세요.
- 다익스트라 알고리즘은 가장 기초적인 두 정점간의 최단거리를 구하는 알고리즘이다. 집합 또는 우선순위 큐를 사용한다.
class Pair implements Comparable<Pair>{
int vertex;
double distance;
Pair(int v, double d){
vertex = v;
distance = d;
}
@Override
public int compareTo(Pair o){
return (int)(distance - o.distance);
}
}
double dijkstra(){
double[] distance = new double[vertexNum];
Arrays.fill(distance,Double.MAX_VALUE);
PriorityQueue<Pair> heap = new PriorityQueue<>();
heap.add(new Pair(0,distance[0]]);
while(!heap.isEmpty()){
Pair p = heap.poll();
if(distance[p.vertex] < p.distance) continue;
for(int i : graph.get(p.vertex).keySet()){
if(distance[i] > distance[p.vertex] + graph.get(p.vertex).get(i)){
distance[i] = distance[p.vertex] + graph.get(p.vertex).get(i);
heap.add(new Pair(i,distance[i]));
}
}
}
return distance[vertexNum-1];- 벨만포드 알고리즘은 최단거리값의 비교를 통해 최단 경로를 구한다.
- 벨만포드는 가중치가 음수일 경우에도 사용가능하다.
'3-2기 스터디 > 기술 면접 대비' 카테고리의 다른 글
| [기술 면접 대비] 5주차- 운영체제 (0) | 2022.05.10 |
|---|---|
| [기술 면접 대비] 4주차 - 데이터베이스 (0) | 2022.05.02 |
| [기술 면접 대비] 3주차- 네트워크 (0) | 2022.04.17 |
| [기술 면접 대비] 1주차-개발 상식 (0) | 2022.04.06 |




댓글