
내용 및 사진 출처: WikiDocs 딥러닝을 이용한 자연어 처리 입문(https://wikidocs.net/book/2155)
1. 기존의 seq2seq 모델의 한계
- seq2seq 모델: encoder(입력 시퀀스를 하나의 벡터로 압축)-decoder 구조(압축된 벡터를 통해서 출력 시퀀스 생성)
- 입력 시퀀스의 정보가 일부 손실 -> 해결책으로 attention 등장
- 이 때, attention을 RNN의 보정을 위한 용도가 아닌 attention만으로 encoder&decoder를 생성하면?
2. Transformer의 주요 하이퍼파라미터
- d_model: Transformer의 인코더와 디코더에서의 정해진 입력과 출력의 크기 의미, 임베딩 벡터의 차원, 각 인코더와 디코더가 다음 층의 인코더와 디코더로 값을 보낼 때도 이 차원 유지
- num_layers: 인코더와 디코더가 각 몇 층으로 구성되어있는지
- num_heads: Transformer에서는 어텐션을 사용할 때, 한 번 하는 것보다 여러 개로 분할해서 병렬로 어텐션 수행, 결과값을 다시 하나로 합치는 방식, 이 때의 병렬 개수
- d_ff: Transformer 내부의 피드 포워드 신경망의 은닉층 크기, 피드포워드 신경망의 입력층과 출력층의 크기는 d_model
3. Transformer
- RNN 사용 X, 인코더-디코더 구조 유지
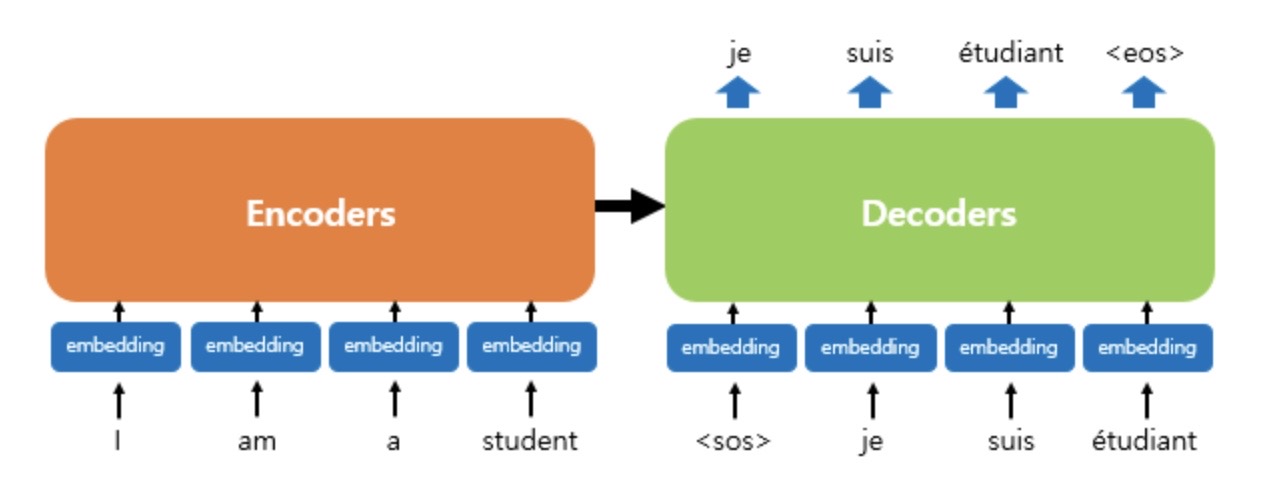
4. Positional Encoding
- Transformer의 입력: Embedding + Positional Encoding
- 기존의 RNN에서는 단어의 위치에 따라 순차적으로 입려받아서 처리하기 때문에 단어의 위치정보를 가질 수 O
- Transformer에서는 단어 입력을 순차적으로 받는 방식이 아니므로 각 단어의 Embedding vector에 위치 정보들을 더하여 모델의 입력으로 사용

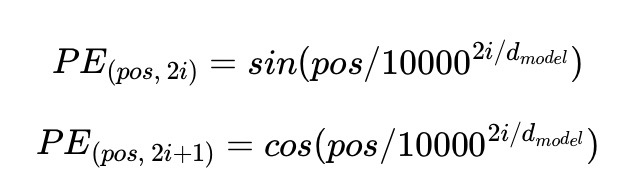
- 임베딩 벡터 내의 각 차원의 인덱스가 짝수일 경우에는 사인 함수, 홀수인 경우에는 코사인 함수를 사용하여 해당 계산값을 임베딩 벡터에 더해준다
5. Attention
- Transformer에서 사용하는 세 가지 어텐션, Encoder self-attention, Masked decoder self-attention, Encoder-decoder attention
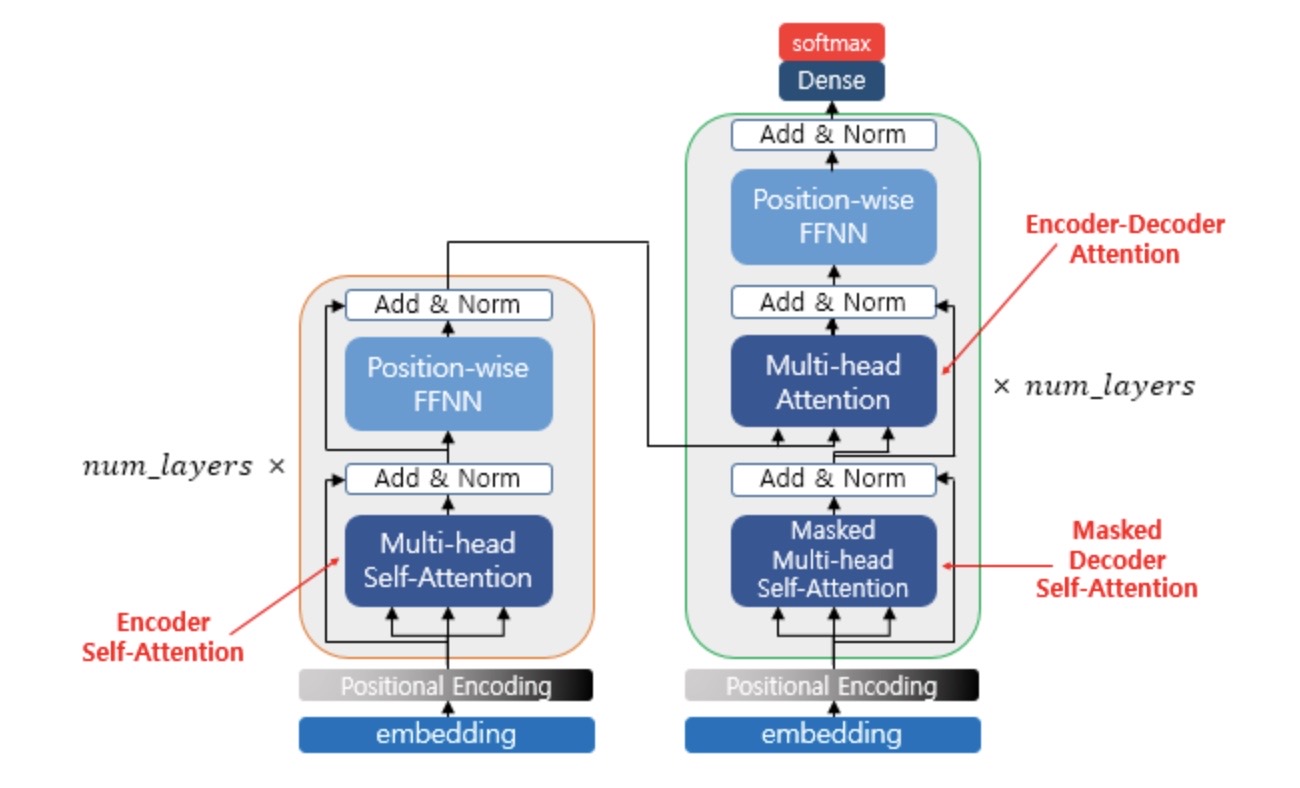
**self-attention: query, key, value 벡터 출처가 동일
6. Encoder

7. Encoder Self-attention
1) self-attention의 의미와 이점: query에 대해서 모든 key와의 유사도를 구해야하는데 기본 attention에서는 가중치로 하여 key와 매핑되어 있는 각 value에 반영하고 모두 가중합하여 attention value를 리턴하는 반면 self-attention은 어텐션을 자기 자신에게 수행하기 대문에 Q,K,V 모두 입력 문장의 모든 단어 벡터들로 동일
2) Q,K,V 벡터 얻기: d_model 차원을 갖는 인코더의 초기 입력 단어 벡터들로부터 더 작은 차원(d_model/num_heads)의 벡터들을 얻는다
3) Scaled dot-product Attention: attention score를 softmax 계층에 통과시키고 그 값과 V 벡터를 곱한 값들을 더하여 attention value인 최종 맥락 벡터 c를 얻는다
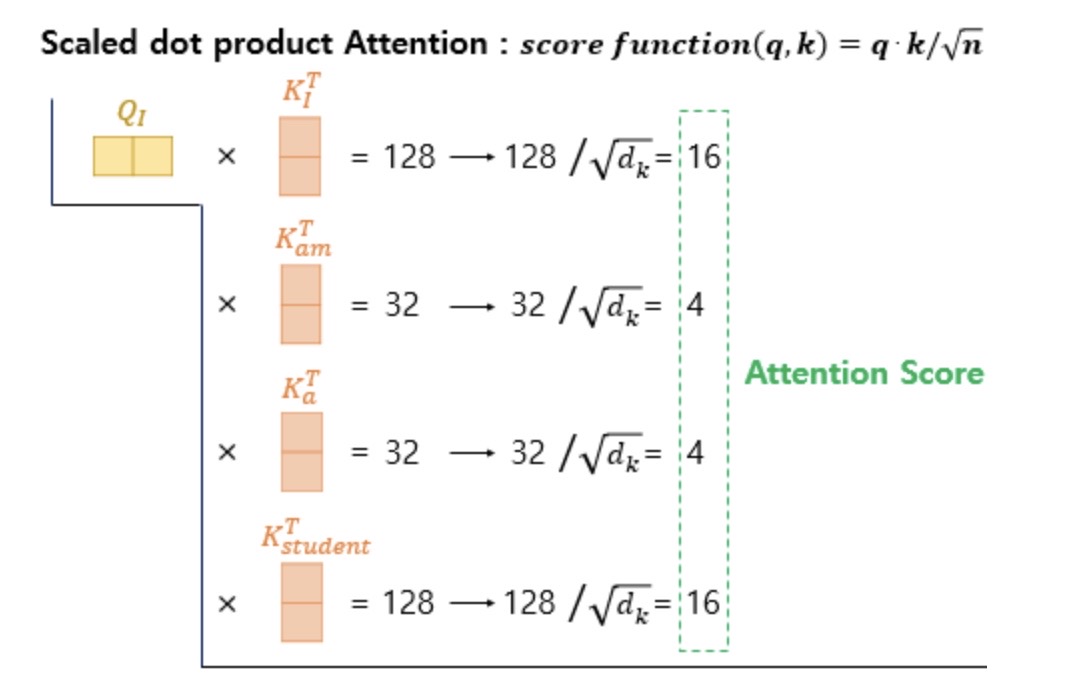
4) 행렬 연산으로 일괄 처리
5) scaled dot-product attention 구현하기
6) Multi-head Attention: 한 번의 어텐션보다 여러 번의 어텐션을 병렬로 수행하는 것이 효과적, 이 때 각각의 어텐션 값 행렬을 어텐션 헤드로, Q,K,V에 대한 가중치 행렬들은 어텐션 헤드마다 전부 다름, 어텐션 병렬로 수행하여 다른 시각으로 정보를 수집할 수 있는 효과, 병렬 어텐션 수행 완료 후 어텐션 헤드 모두 연결
7) Multi-head attention 구현하기
8) Padding Mask: 입력 문장에 <PAD> 토큰이 있을 경우 어텐션에서 사실상 제외하기 위한 연산, 이에 대해서는 유사도를 구하지 않도록 Masking
8. Position-wise FFNN(인코더의 두 번째 서브층)
- 인코더와 디코더에서 공통적으로 가지고 있는 서브층
- Fully-connected FFNN
9. Residual connection & Layer Normalization
1) Residual connection: skip 연결, short cut과 동일, 손실되는 데이터 방지 효과, 서브층의 입력과 출력을 더하는 것
2) Layer Normalization: 텐서의 마지막 차원에 대해서 평균과 분산을 구하고 이를 가지고 수식을 통해 값을 정규화하여 학습을 도움
10. 인코더 구현하기: 멀티 헤드 어텐션 서브층 & 피드 포워드 시경망 서브층 -> 드롭 아웃&잔차 연결&층 정규화
11. 인코더 쌓기: 인코더 층을 num_layers 개만큼 쌓고 마지막 인코더 층에서 얻은 (seq_len,d_model) 크기의 행렬을 디코더로 보내줌
12. 인코더에서 디코더로: 디코더 또한 num_layers만큼 연산, 이 때마다 인코더가 보낸 출력을 각 디코더 층 연상에서 사용
13. 디코더의 첫번째 서브층: 셀프 어텐션과 룩-어헤드 마스크
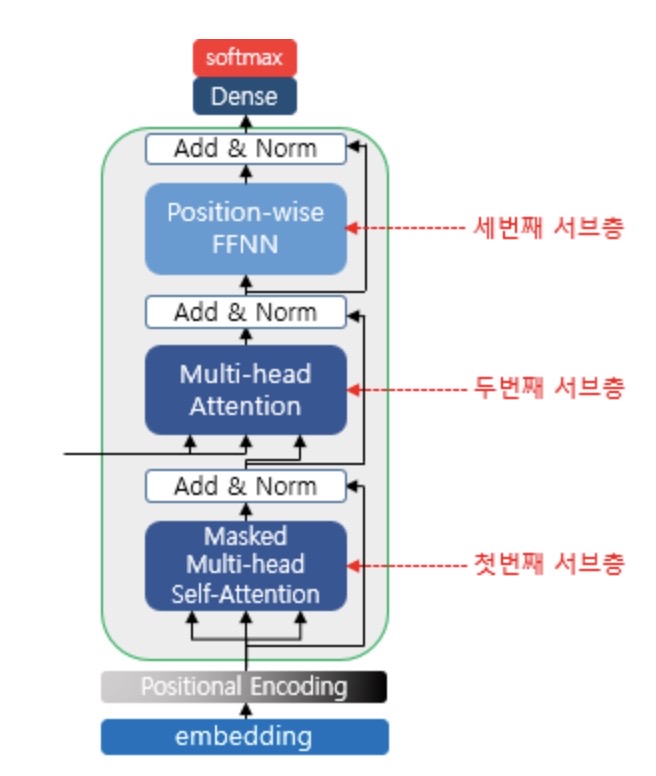
- 트랜스포커 또한 seq2seq와 마찬가지로 teacher forcing을 사용하여 훈련된다
- 디코더는 입력받은 문장 행렬로부터 각 시점의 단어를 예측하도록 훈력
- 한번에 입력 문장이 입력되므로 현재 시점의 단어를 예측하고자 할 때 입력 문장 행렬로부터 미래 시점의 단어까지 참고 가능
-> 현재 시점의 예측보다 미래의 단어들을 참고하지 못하도록 look-ahead mask 도입
- 이 때 look-ahead mask한다고 해서 패딩 마스크가 불필요한 건 X
14. 디코더의 두번째 서브층: 인코더-디코더 어텐션
- Multi-head, self-attention X(query-디코더, key/value-인코더)
15. 디코더 구현하기: 총 3개의 서브층으로 구성, 첫번째, 두번째 서브층은 멀티 헤드 어텐션, 세 개의 서브층 모두 서브층 연산 후 드롭 아웃, 잔차 연결, 층 정규화 수행
16. 디코더 쌓기: num_layers 만큼 쌓기
17. transformer 구현하기
- 인코더의 출력은 디코더의 인코더-디코더 어텐션에서 사용되기 위해 디코더로 전달
- 디코더 끝단에는 다중 클래스 분류 문제를 풀 수 있도록 vocab-size만큼의 뉴런을 갖는 출력층 추가
18. transformer 하이퍼파라미터 정하기
19. 손실 함수 정의하기
20. 학습률
- Learning rate Scheduler: 미리 학습 일정을 정해두고 그 일정에 따라 학습률이 조정되는 방법
- Transformer 경우, 사용자가 정한 단계까지는 학습률 증가, 일정 단계에 이르면 학습률을 점차적으로 떨어뜨리는 방식

'3-2기 스터디 > NLP 입문' 카테고리의 다른 글
| [6주차] NLP Chapter 7. RNN을 사용한 문장 생성 - 8. 어텐션 (0) | 2022.05.30 |
|---|---|
| [9주차] 딥러닝을 이용한 자연어처리 입문 Chap.17 BERT (0) | 2022.05.30 |
| [7주차] 딥러닝을 이용한 자연어처리 입문 Chap.2 텍스트 전처리 (0) | 2022.05.30 |
| [5주차] NLP Chapter 5.2 RNN이란 ~ 6. 게이트가 추가된 RNN (0) | 2022.05.02 |
| [4주차] NLP Chapter 4. word2vec 속도 개선 ~ 5.2 RNN이란 (0) | 2022.05.02 |

댓글