
Fullstack Deeplearning 강의를 듣고 정리한 내용입니다.
https://fullstackdeeplearning.com/spring2021/lecture-7/
딥러닝 모델 문제 해결이 어려운 이유
- 버그가 존재하는지 알아차리기 어렵다.
- Data, Model, Infrastructure 등 모델 성능을 떨어뜨리는 원인이 다양함
- hyperparameters and dataset makeup에 성능이 민감함
모델 성능이 낮은 이유
- Implementation bugs : Most DL bugs are invisible
- Models are sensitive to hyperparameters (learning rate varies a lot by hyperparameters)
- Data-Model fit
- Data construction issues : Constructing good datasets is hard
-Not enough data
-Class imbalances
-Noisy labels
-Train/Test from different distributions
Neural Network troubleshooting 방법
다음의 과정을 고려한다.

1. 단순하게 시작하기
- 심플한 모델 구조로 시작한다.
Image의 경우, Start with LeNet-like architecture & Consider using ResNet later
Sequence 데이터의 경우, Transformer model or WaveNet-like model
멀티모달 데이터의 경우, Map each into a lower dimension space - Concatenate - Pass through FC layers - 시작할 때 default 값들
Adam optimizer with learning rate 3e-4
Activations : Relu for FC and conv models, tanh for LSTMs
Regularization & Data normalization Start with none (버그의 가장 흔한 원인 중 하나라고 한다!) - Normalize scale of input data
Images Scale values to [0,1] or [-0.5, 0.5] (e.g. By dividing by 255) - 작은 스케일로 시작한다.
Start with small training set : Create a simpler synthetic training set
2. Implement & Debug
가장 자주 발생하는 5가지 버그

모델 돌려보기
debugger 한줄씩 살펴보기 & shape 에러, casting 에러, OOM 에러
- Start with lightweight implementation
- Use off-the-shelf components (e.g. keras tf.layers.dense instead of tf.nn.relu(tf.matmul(W,x)))
- Shape mismatch & Casting issue (Step through model creation & inference in a debugger)
Tools
Pytorch ipdb
tensorflow trickier tfdb - Out Of Memory (Scale back one-by-one)
Overfit a single batch
Look for corrupted data, over-regularization, errors
- Error goes up
- Error explodes
- Error oscillates
- Error plateaus
알려진 결과와 비교하기
Iterate until model performs up to expectations
3. 모델 평가
distribution shift
Use 2 validation sets : one sampled from training distribution & one from test distribution
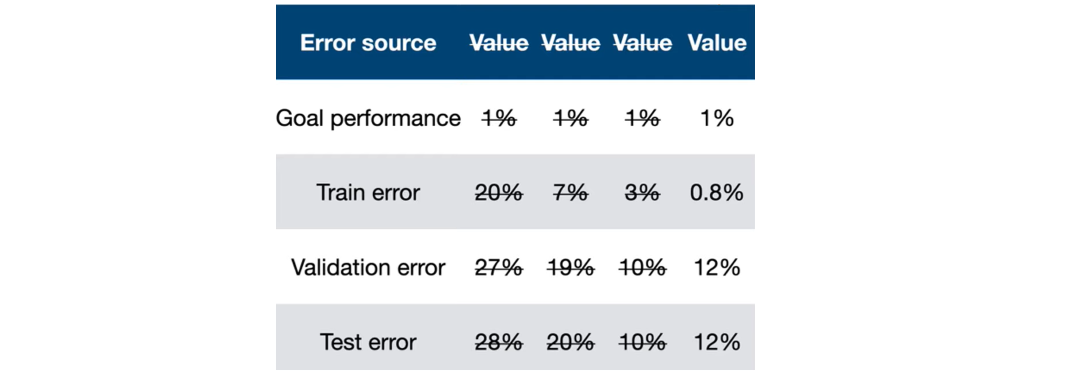
Train-val error & Test-val error Proxy for how much distribution shift is hurting the model performance
Test error 는 irreducible error + bias + variance + distribution shift + validation overfitting로 볼 수 있다

4. 모델, 데이터 개선
Underfitting 해결하기
- Make the model bigger (add layers / more units)
- Reduce regularization
- Choose different architecture (closer to SOTA model)
- Tune learning rate & hyperparameters
Overfitting 해결하기

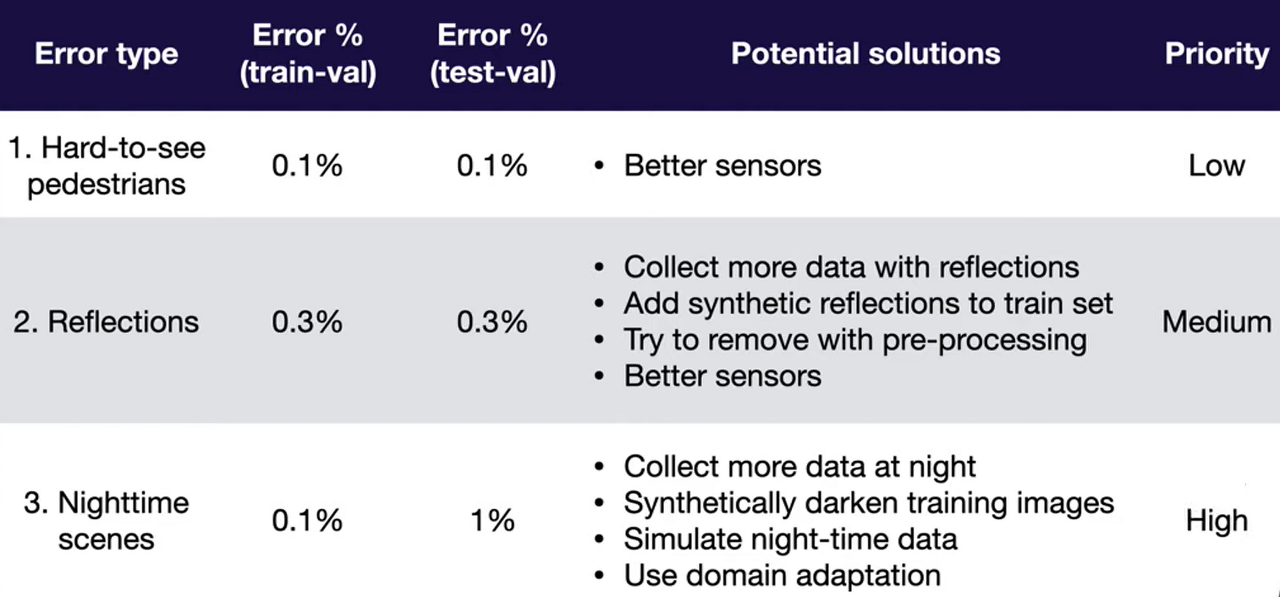
Address distribution shift
- Analyze test-val set errors & collect or synthesize more training data to compensate
- Apply domain adaptation techniques to train & test distributions
e.g.

Domain adaptation
Techniques to train on source distribution and generalize to another target using only unlabeled data ot limited labeled data.
- Correlation Alignment
- Domain confusion
- cycleGAN
Re-balance datasets
- If val looks significantly better than test, model overfits to the val set.
- Due to small val sets / Lots of hyperparameter tuning
- Recollect validation data or resample
'3-2기 스터디 > MLOps' 카테고리의 다른 글
| [8주차] Data Management (0) | 2022.06.29 |
|---|---|
| [5주차] ML Projects (0) | 2022.05.31 |
| [4주차] Transformers (0) | 2022.05.17 |
| [3주차] RNNs (0) | 2022.05.10 |
| [2주차] CNNs (0) | 2022.05.03 |




댓글